0x00 简介 曾经对宽字节注入的了解很浅显,只知道在单引号前面加个%df之类的
所以,可能会存在很多错误的认知,重新梳理一遍
0x01 基础 什么是宽字节 如果一个字符的大小是一个字节的,称为窄字节;如果一个字符的大小是两个字节的,成为宽字节
像GB2312、GBK、GB18030、BIG5、Shift_JIS等这些编码都是常说的宽字节,也就是只有两字节
英文默认占一个字节,中文占两个字节
像utf8之类的占三个字节,可称为多字节
这里提一下为什么存在gbk的注入,不存在utf8的呢,都是多字节
这主要和编码的范围有关系,比如在php中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 static unsigned int check_mb_utf8_sequence (const char *start, const char *end) zend_uchar c; if (start >= end) { return 0 ; } c = (zend_uchar) start[0 ]; if (c < 0x80 ) { return 1 ; } if (c < 0xC2 ) { return 0 ; } if (c < 0xE0 ) { if (start + 2 > end) { return 0 ; } if (!(((zend_uchar)start[1 ] ^ 0x80 ) < 0x40 )) { return 0 ; } return 2 ; } if (c < 0xF0 ) { if (start + 3 > end) { return 0 ; } if (!(((zend_uchar)start[1 ] ^ 0x80 ) < 0x40 && ((zend_uchar)start[2 ] ^ 0x80 ) < 0x40 && (c >= 0xE1 || (zend_uchar)start[1 ] >= 0xA0 ))) { return 0 ; } return 3 ; } if (c < 0xF5 ) { if (start + 4 > end) { return 0 ; } if (!(((zend_uchar)start[1 ] ^ 0x80 ) < 0x40 && ((zend_uchar)start[2 ] ^ 0x80 ) < 0x40 && ((zend_uchar)start[3 ] ^ 0x80 ) < 0x40 && (c >= 0xf1 || (zend_uchar)start[1 ] >= 0x90 ) && (c <= 0xf3 || (zend_uchar)start[1 ] <= 0x8F ))) { return 0 ; } return 4 ; } return 0 ; }
可以算的出来最后一个字符不可能出现5C或者22或者27
什么是宽字节注入 宽字节注入是利用mysql的一个特性,mysql在使用GBK编码(GBK就是常说的宽字节之一,实际上只有两字节)的时候,会认为两个字符是一个汉字(前一个ascii码要大于128,才到汉字的范围)
GBK首字节对应0×81-0xFE,尾字节对应0×40-0xFE(除0×7F),例如%df和%5C会结合;GB2312是被GBK兼容的,它的高位范围是0xA1-0xF7,低位范围是0xA1-0xFE(0x5C不在该范围内),因此不能使用编码吃掉%5c
常见转义函数与配置:
addslashes
mysql_real_escape_string
mysql_escape_string
php.ini中magic_quote_gpc的配置
宽字节注入发生的位置就是PHP发送请求到MYSQL时字符集使用character_set_client设置值进行了一次编码。在使用PHP连接MySQL的时候,当设置character_set_client = gbk时会导致一个编码转换的问题,也就是我们熟悉的宽字节注入
这里其实说编码转换并不合理
实际上应该是一个按照编码识别的过程,期间并不会有任何的转码操作
MySQL相关 Mysql中有个连接层,何为连接层?在MYSQL中,有一个中间层的结构,负责客户端和服务器之间的连接,称为连接层 交互的过程如下:
客户端(这里指php)以某种字符集生成的SQL语句发送至服务器端(这里指Mysql),这个“某种字符集”其实是任意规定的,PHP作为客户端连接MYSQL时,这个字符集就是PHP文件默认的编码。
服务器(Mysql)会将这个SQL语句转为连接层的字符集。问题在于MYSQL是怎么知道我们传过来的这个SQL语句是什么编码呢?这时主要依靠两个MYSQL的内部变量来表示,一个是character_set_client(客户端的字符集)和character_set_connection(连接层的字符集)
这里曾经看到的一些文章指出,是对sql语句进行编码转化,这样说比较合理,但是实际测试其实更像只是针对sql语句中的字符部分,关键字之类的并不参与
并且在mysql中反斜杠可以转移任何字符,包括gbk编码的第一个字节
这就导致当第一个字节前面存在反斜杠时,就失去了原本的意义
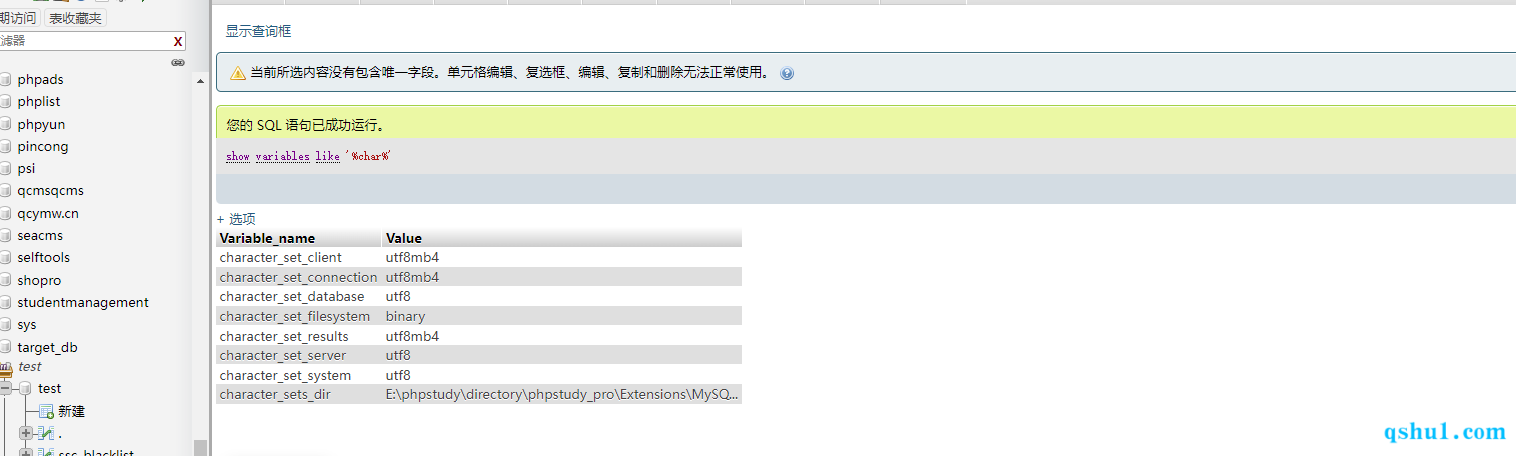
查看mysql字符集
1 show variables like '%char%';
可以通过如下语句设置
相当于下面的三句命令
1 2 3 set character_set_client = gbk; set character_set_results = gbk; set character_set_connection = gbk;
0x02 函数差异 这里主要还是介绍php中的函数差异
addslashes
mysql_real_escape_string
PDO::quote
其实存在大于5.3(大概,没细看)的版本只有addslashes是存在宽字节注入问题的,这种与数据库版本应该没有关系(犹豫一手),当设置gbk编码时,按照gbk解码无可厚非
addslashes 其实这个函数实现的很简单
没有什么好解释的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 PHP_FUNCTION(addslashes) { zend_string *str; ZEND_PARSE_PARAMETERS_START(1 , 1 ) Z_PARAM_STR(str) ZEND_PARSE_PARAMETERS_END(); if (ZSTR_LEN(str) == 0 ) { RETURN_EMPTY_STRING(); } RETURN_STR(php_addslashes(str)); }
php_addslashes函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 PHPAPI zend_string *php_addslashes (zend_string *str) # endif char *target; const char *source, *end; size_t offset; zend_string *new_str; if (!str) { return ZSTR_EMPTY_ALLOC(); } source = ZSTR_VAL(str); end = source + ZSTR_LEN(str); while (source < end) { switch (*source) { case '\0' : case '\'' : case '\"' : case '\\' : goto do_escape; default : source++; break ; } } return zend_string_copy(str); do_escape: offset = source - (char *)ZSTR_VAL(str); new_str = zend_string_safe_alloc(2 , ZSTR_LEN(str) - offset, offset, 0 ); memcpy (ZSTR_VAL(new_str), ZSTR_VAL(str), offset); target = ZSTR_VAL(new_str) + offset; while (source < end) { switch (*source) { case '\0' : *target++ = '\\' ; *target++ = '0' ; break ; case '\'' : case '\"' : case '\\' : *target++ = '\\' ; default : *target++ = *source; break ; } source++; } *target = '\0' ; if (ZSTR_LEN(new_str) - (target - ZSTR_VAL(new_str)) > 16 ) { new_str = zend_string_truncate(new_str, target - ZSTR_VAL(new_str), 0 ); } else { ZSTR_LEN(new_str) = target - ZSTR_VAL(new_str); } return new_str; } #endif
其实就是在四个字符之前添加了\,进行转义
并没有其他过多的操作
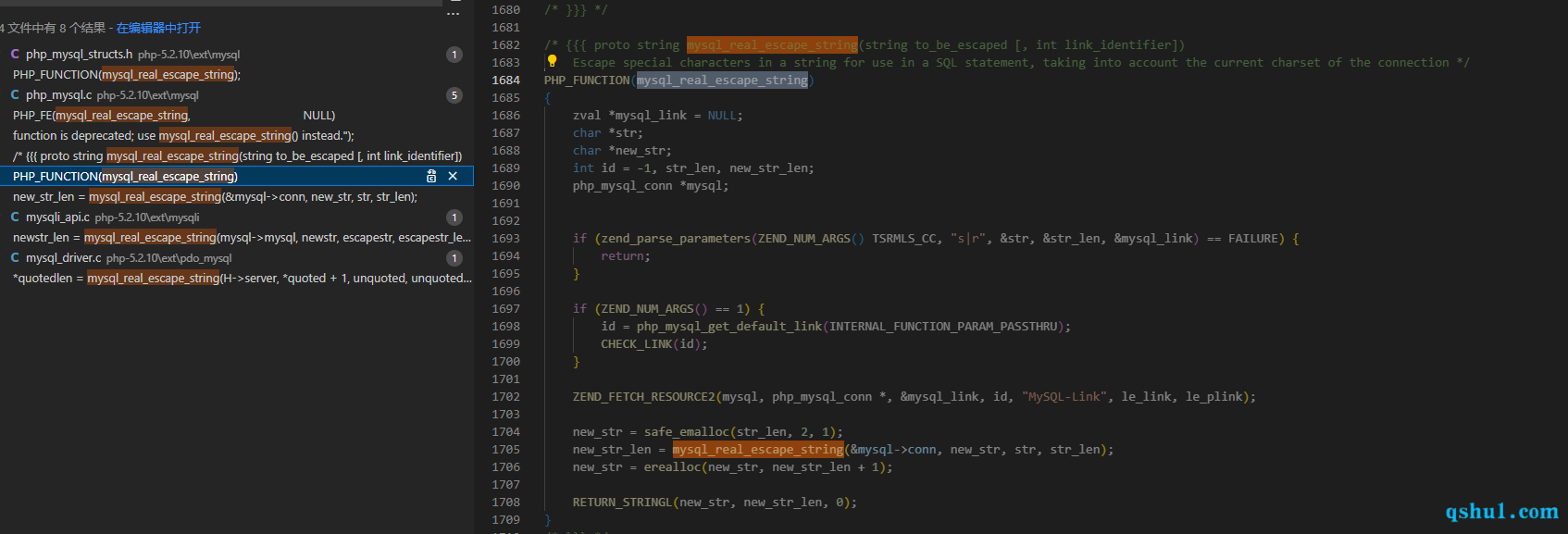
quote 其实如下三种处理都是一样的,最终都是调用的mysql_real_escape_string
quote
mysql_real_escape_string
mysqli_real_escape_string
就以quote来说
好像不太直白,还是看mysqli_real_escape_string
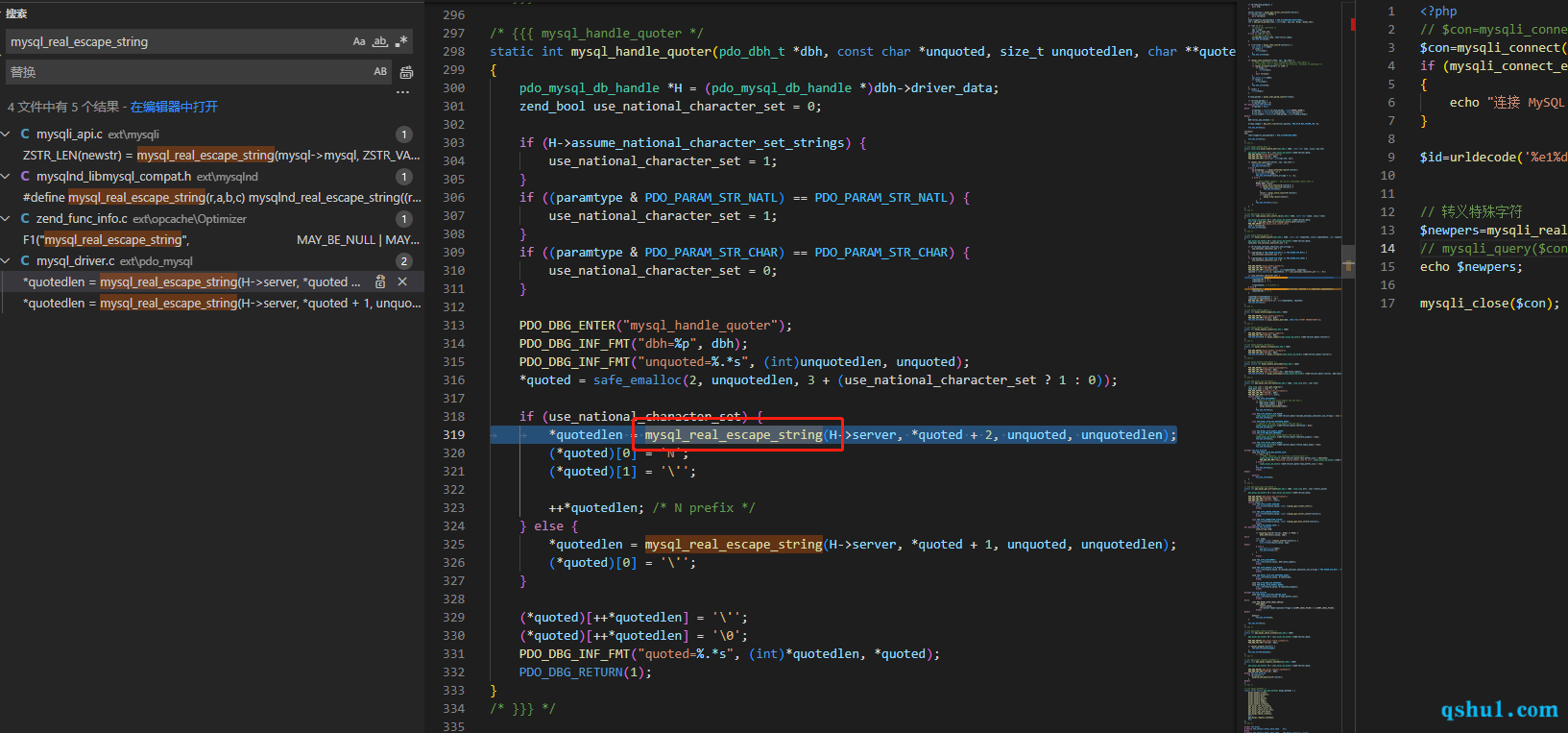
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 PHP_FUNCTION(mysqli_real_escape_string) { MY_MYSQL *mysql; zval *mysql_link = NULL ; char *escapestr; size_t escapestr_len; zend_string *newstr; if (zend_parse_method_parameters(ZEND_NUM_ARGS(), getThis(), "Os" , &mysql_link, mysqli_link_class_entry, &escapestr, &escapestr_len) == FAILURE) { return ; } MYSQLI_FETCH_RESOURCE_CONN(mysql, mysql_link, MYSQLI_STATUS_VALID); newstr = zend_string_alloc(2 * escapestr_len, 0 ); ZSTR_LEN(newstr) = mysql_real_escape_string(mysql->mysql, ZSTR_VAL(newstr), escapestr, escapestr_len); newstr = zend_string_truncate(newstr, ZSTR_LEN(newstr), 0 ); RETURN_NEW_STR(newstr); }
这是在php的7.3版本
1 2 3 #define mysql_real_escape_string(r,a,b,c) mysqlnd_real_escape_string((r), (a), (b), (c)) #define mysqlnd_real_escape_string(conn, newstr, escapestr, escapestr_len) \ ((conn)->data)->m->escape_string((conn)->data, (newstr), (escapestr), (escapestr_len))
然后会进入,其实看到这里大概就可以猜到,这个单纯的addslashes不一样了,因为出现了这么多charset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 MYSQLND_METHOD(mysqlnd_conn_data, escape_string)(MYSQLND_CONN_DATA * const conn, char * newstr, const char * escapestr, size_t escapestr_len) { const size_t this_func = STRUCT_OFFSET(MYSQLND_CLASS_METHODS_TYPE(mysqlnd_conn_data), escape_string); zend_ulong ret = FAIL; DBG_ENTER("mysqlnd_conn_data::escape_string" ); DBG_INF_FMT("conn=%llu" , conn->thread_id); if (PASS == conn->m->local_tx_start(conn, this_func)) { DBG_INF_FMT("server_status=%u" , UPSERT_STATUS_GET_SERVER_STATUS(conn->upsert_status)); if (UPSERT_STATUS_GET_SERVER_STATUS(conn->upsert_status) & SERVER_STATUS_NO_BACKSLASH_ESCAPES) { ret = mysqlnd_cset_escape_quotes(conn->charset, newstr, escapestr, escapestr_len); } else { ret = mysqlnd_cset_escape_slashes(conn->charset, newstr, escapestr, escapestr_len); } conn->m->local_tx_end(conn, this_func, PASS); } DBG_RETURN(ret); }
至于mysqlnd_cset_escape_quotes或者mysqlnd_cset_escape_slashes这个就是模式的问题
比如单引号,分别会处理成如下格式
接下来就是转义的主体函数了,可以看到除了addslashes的四个字符外
额外添加了
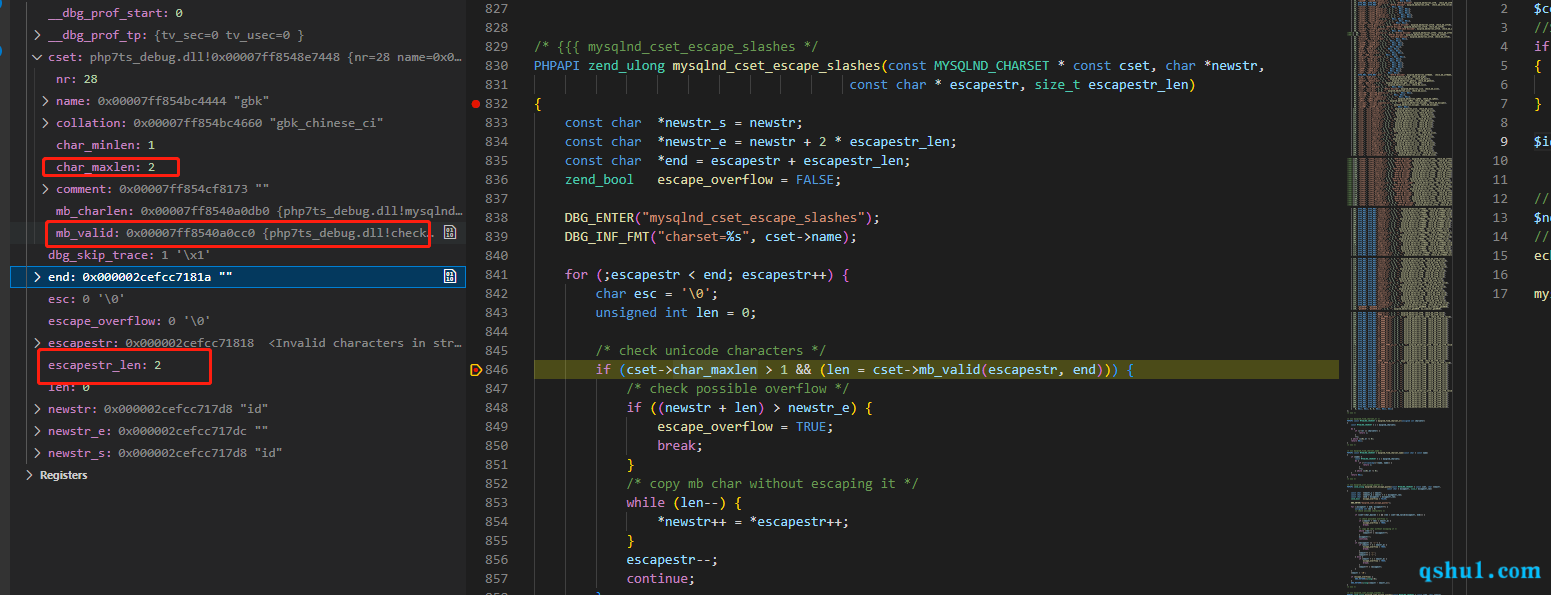
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 PHPAPI zend_ulong mysqlnd_cset_escape_slashes (const MYSQLND_CHARSET * const cset, char *newstr, const char * escapestr, size_t escapestr_len) const char *newstr_s = newstr; const char *newstr_e = newstr + 2 * escapestr_len; const char *end = escapestr + escapestr_len; zend_bool escape_overflow = FALSE; DBG_ENTER("mysqlnd_cset_escape_slashes" ); DBG_INF_FMT("charset=%s" , cset->name); for (;escapestr < end; escapestr++) { char esc = '\0' ; unsigned int len = 0 ; if (cset->char_maxlen > 1 && (len = cset->mb_valid(escapestr, end))) { if ((newstr + len) > newstr_e) { escape_overflow = TRUE; break ; } while (len--) { *newstr++ = *escapestr++; } escapestr--; continue ; } if (cset->char_maxlen > 1 && cset->mb_charlen(*escapestr) > 1 ) { esc = *escapestr; } else { switch (*escapestr) { case 0 : esc = '0' ; break ; case '\n' : esc = 'n' ; break ; case '\r' : esc = 'r' ; break ; case '\\' : case '\'' : case '"' : esc = *escapestr; break ; case '\032' : esc = 'Z' ; break ; } } if (esc) { if (newstr + 2 > newstr_e) { escape_overflow = TRUE; break ; } *newstr++ = '\\' ; *newstr++ = esc; } else { if (newstr + 1 > newstr_e) { escape_overflow = TRUE; break ; } *newstr++ = *escapestr; } } *newstr = '\0' ; if (escape_overflow) { DBG_RETURN((ulong)~0 ); } DBG_RETURN((ulong)(newstr - newstr_s)); }
这里影响宽字节注入的还是cset->mb_charlen这个地址对应的函数
看到上面的函数,添加转义的关键点就是,要么不存在esc,要么newstr+2的地址大于newstr_e
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if (esc) { if (newstr + 2 > newstr_e) { escape_overflow = TRUE; break ; } *newstr++ = '\\' ; *newstr++ = esc; } else { if (newstr + 1 > newstr_e) { escape_overflow = TRUE; break ; } *newstr++ = *escapestr; }
而newstr_e的定义是
1 const char *newstr_e = newstr + 2 * escapestr_len;
而gbk编码最少两个字节,一个字节白搭,就算只有一个字节也是newstr + 2 == newstr_e
下面的代码会,但只是单纯的处理汉字
1 2 3 4 5 6 7 8 9 10 11 12 13 if (cset->char_maxlen > 1 && (len = cset->mb_valid(escapestr, end))) { if ((newstr + len) > newstr_e) { escape_overflow = TRUE; break ; } while (len--) { *newstr++ = *escapestr++; } escapestr--; continue ; }
这里就以%df%27为例
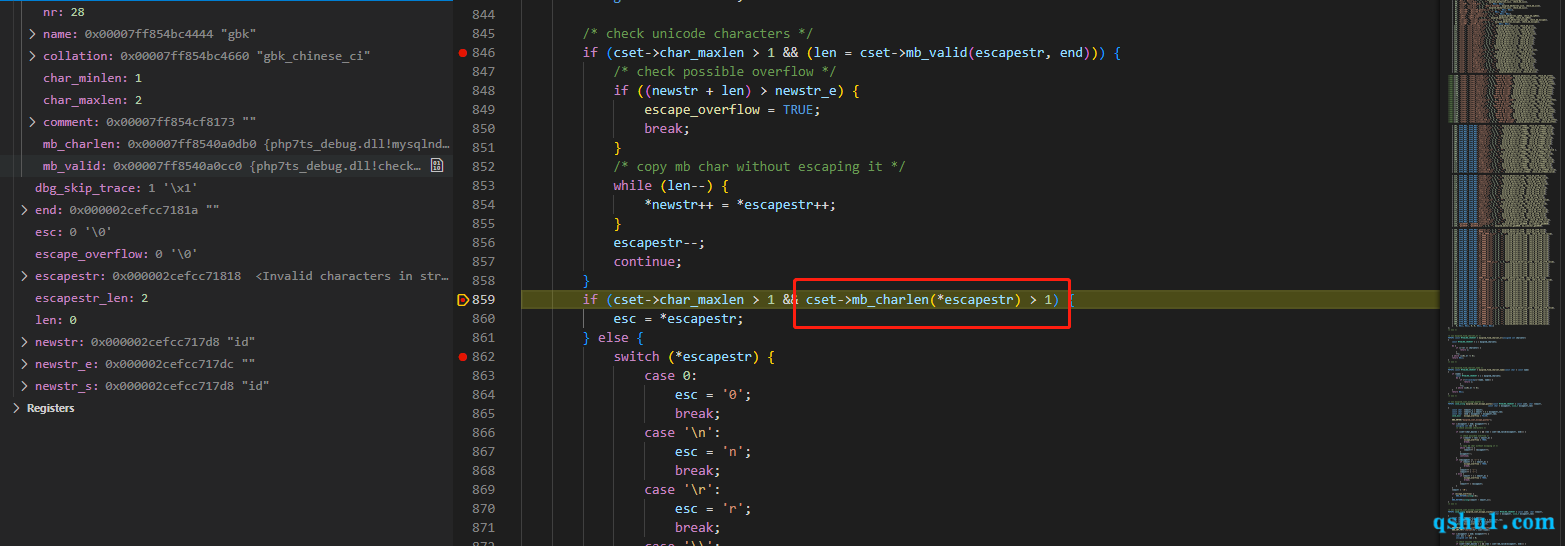
这里的mb_calid对应的是check_mb_gbk
1 2 3 4 5 6 7 #define valid_gbk_head(c) (0x81<=(zend_uchar)(c) && (zend_uchar)(c)<=0xFE) #define valid_gbk_tail(c) ((0x40<=(zend_uchar)(c) && (zend_uchar)(c)<=0x7E) || (0x80<=(zend_uchar)(c) && (zend_uchar)(c)<=0xFE)) static unsigned int check_mb_gbk (const char *start, const char *end) return (valid_gbk_head(start[0 ]) && (end) - (start) > 1 && valid_gbk_tail(start[1 ])) ? 2 : 0 ; }
这就是中文的所有编码,其实这里是为了让esc为空就是说需要返回值为2
其中start[0]对应的就是%df,start[1]对应的是%27
组不成汉字,这是因为判断在单引号转义之前,如果在之后,那就可以了
所以此处无法利用的
进入另外一个方法
1 2 3 4 static unsigned int mysqlnd_mbcharlen_gbk (unsigned int gbk) return (valid_gbk_head(gbk) ? 2 : 1 ); }
这个需要返回1,也是白搭
所以这里无法利用的
针对我们的输入,程序会进行如下操作
%df+%27\+%df+%27\+%df+\+%27
在根据之前说到的关于mysql,去读字符传编码从第一个字符开始,%df将是单独的一个字符
无法逃逸单引号了
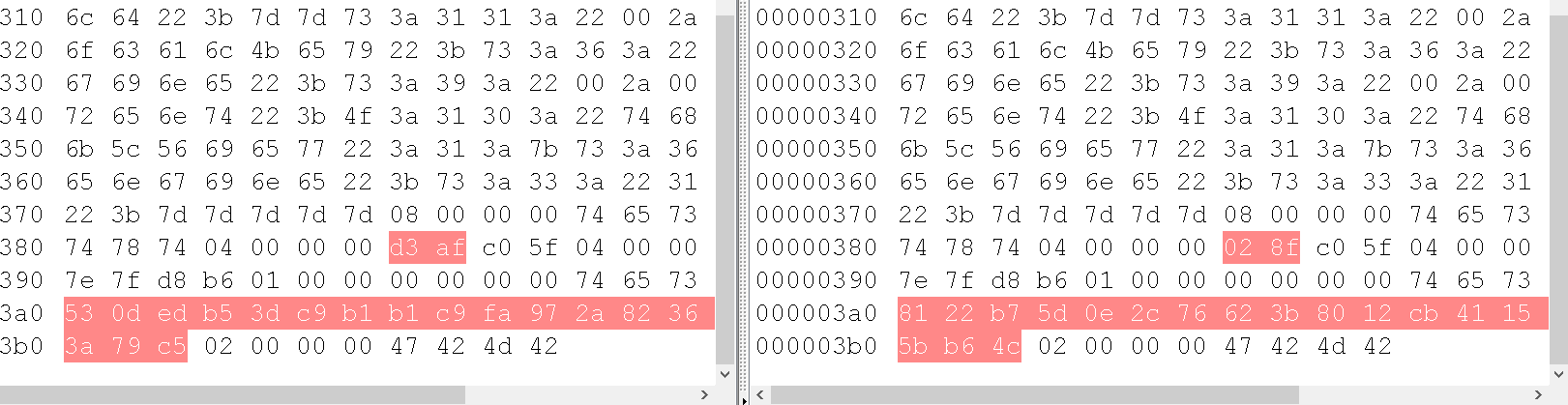
其实这就应该是对早期版本的修复
早期的php版本对这块的处理是没有中文字符的,php5.2版本如下
0x03 end 虽然没找到利用差异,但是对gbk的宽字节注入算是有了部分了解
再次痛失一个软件的0day。。。